SS-LR 协议#
算法流程#
算法分为2阶段,第一阶段为握手过程,第二阶段为算法主体,其流程如下:
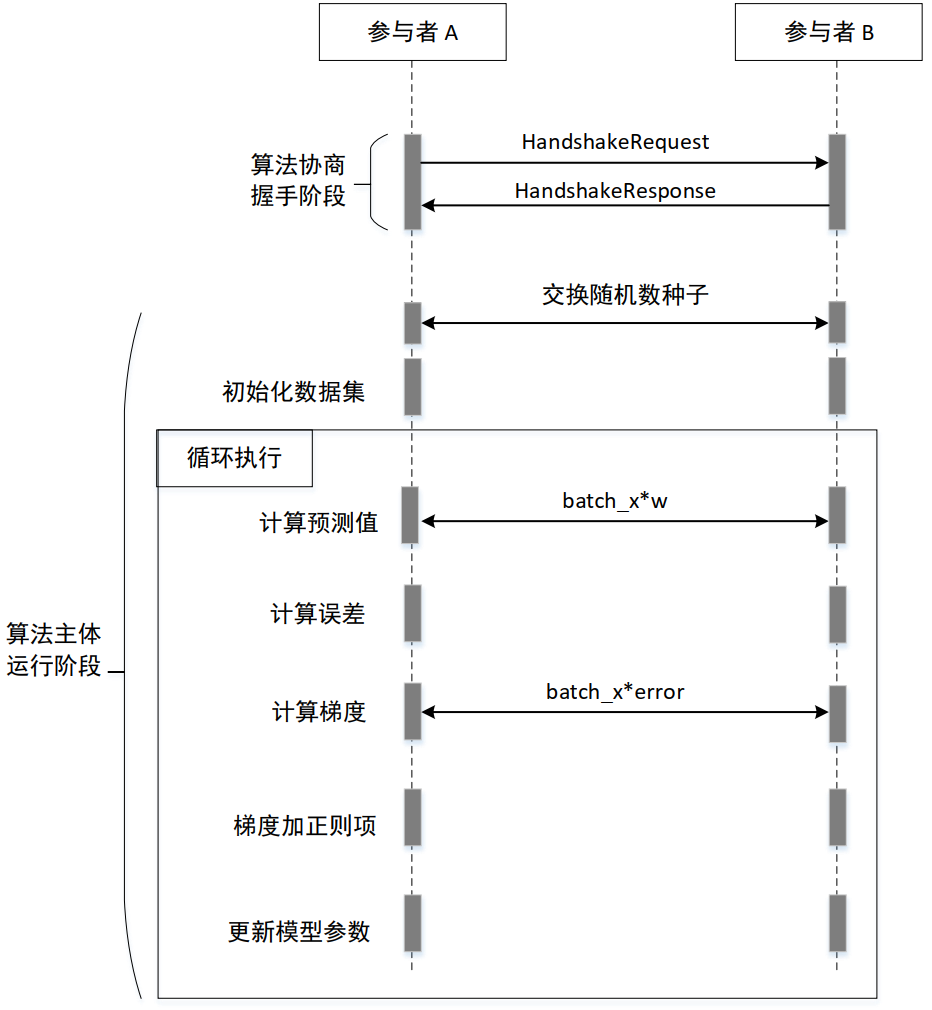
握手过程#
握手协议#
握手所用的 HandshakeRequest 定义如下:
1// unified protocol for interconnection
2message HandshakeRequest {
3 // 握手请求版本号, 当前等于 2
4 int32 version = 1;
5
6 //** META INFO **//
7
8 // The sender's rank
9 int32 requester_rank = 2;
10
11 //** AI/BI 算法层 **//
12
13 // enum AlgoType
14 repeated int32 supported_algos = 3;
15
16 // 算法详细握手参数,与 supported_algos 一一对应
17 // SS-LR:learning_rate,optimizer,normalize
18 // ECDH-PSI:Nothing,skip
19 repeated google.protobuf.Any algo_params = 4;
20
21 //** 安全算子层 **//
22
23 // AI/BI 算法所需的 op 列到此处
24 // op = enum OpType
25 // ECDH-PSI:Nothing,skip
26 repeated int32 ops = 5;
27 repeated google.protobuf.Any op_params = 6;
28
29 //** 密码协议层 **//
30
31 // protocol_family = enum ProtocolFamily
32 // SS: Protocol: [Semi2K, ABY3], FieldType, BeaverConfig, SerializeFormat
33 // ECC: Hash2Curve, EcGroup, SerializeFormat
34 // PHE: Protocol: [Paillier, EcElgamal], SerializeFormat
35 repeated int32 protocol_families = 7;
36 repeated google.protobuf.Any protocol_family_params = 8;
37
38 //** 数据 IO **//
39
40 // 定义 AI/BI 算法的输入和结果输出格式,不包括中间交互数据的格式
41 // PSI: item_count、result_to_rank
42 // SS-LR: sample_size、feature_num、has_label, etc.
43 google.protobuf.Any io_param = 9;
44}
HandshakeRequest 主要包括以下信息:
协议版本号
请求方的传输层 rank 值
想使用的具体算法,比如使用 SS-LR
每类算法的详细参数,比如 SS-LR 需要说明优化器类型、正则项等参数
用到的安全算子的类型,比如 Sigmoid
每个安全算子的详细参数,比如 Sigmoid 需要说明采用的拟合算法
用到的密码协议族,比如 SS 协议族
每个协议族的详细参数,比如 SS 协议族需要说明协议种类、整数环比特数等参数
算法的输入和结果输出格式,比如 SS-LR 需要说明样本数量、特征数量等参数
HandshakeRequest 中的 supported_algos 字段的定义如下:
1enum AlgoType {
2 ALGO_TYPE_UNSPECIFIED = 0;
3 ALGO_TYPE_ECDH_PSI = 1;
4 ALGO_TYPE_SS_LR = 2;
5}
如果算法是 SS-LR,则 HandshakeRequest 中的 algo_params 字段格式如下:
1message LrHyperparamsProposal {
2 repeated int32 supported_versions = 1;
3
4 // 支持哪些优化器类型
5 // Ref: enum Optimizer
6 repeated int32 optimizers = 2;
7
8 // Ref: enum LastBatchPolicy
9 repeated int32 last_batch_policies = 3;
10
11 bool use_l0_norm = 4;
12 bool use_l1_norm = 5;
13 bool use_l2_norm = 6;
14}
LrHyperparamsProposal 中的 optimizers 字段的定义如下:
1// Optimizer list
2enum Optimizer {
3 OPTIMIZER_UNSPECIFIED = 0;
4 OPTIMIZER_SGD = 1;
5 OPTIMIZER_MOMENTUM = 2;
6 OPTIMIZER_ADAGRAD = 3;
7 OPTIMIZER_ADADELTA = 4;
8 OPTIMIZER_RMSPROP = 5;
9 OPTIMIZER_ADAM = 6;
10 OPTIMIZER_ADAMAX = 7;
11 OPTIMIZER_NADAM = 8;
12}
LrHyperparamsProposal 中的 last_batch_policies 字段的定义如下:
1// Policy to process the partial last batch of each epoch
2enum LastBatchPolicy {
3 LAST_BATCH_POLICY_UNSPECIFIED = 0;
4 LAST_BATCH_POLICY_DISCARD = 1;
5}
HandshakeRequest 中的 ops 字段的定义如下:
1enum OpType {
2 OP_TYPE_UNSPECIFIED = 0;
3 OP_TYPE_SIGMOID = 1;
4}
如果安全算子类型是 Sigmoid,则 HandshakeRequest 中的 op_params 字段格式如下:
1message SigmoidParamsProposal {
2 repeated int32 supported_versions = 1;
3
4 // enum SigmoidMode
5 repeated int32 sigmoid_modes = 2;
6}
SigmoidParamsProposal 中的 sigmoid_modes 字段的定义如下:
1// Sigmoid approximation method.
2enum SigmoidMode {
3 SIGMOID_MODE_UNSPECIFIED = 0;
4
5 // Minimax approximation one order, f(x) = 0.5 + 0.125 * x
6 SIGMOID_MODE_MINIMAX_1 = 1;
7}
HandshakeRequest 中的 protocol_families 字段的定义如下:
1enum ProtocolFamily {
2 PROTOCOL_FAMILY_UNSPECIFIED = 0;
3 PROTOCOL_FAMILY_ECC = 1;
4 PROTOCOL_FAMILY_SS = 2;
5 PROTOCOL_FAMILY_PHE = 3;
6}
如果协议族是 SS,则 HandshakeRequest 中的 protocol_family_params 字段格式如下:
1message SSProtocolProposal {
2 repeated int32 supported_versions = 1;
3 repeated int32 supported_protocols = 2; // enum ProtocolKind
4
5 repeated int32 field_types = 3; // enum FieldType
6 repeated TruncationModeProposal trunc_modes = 4;
7 repeated PrgConfigProposal prg_configs = 5;
8
9 // 秘密分享分片的序列化格式, enum ShardSerializeFormat
10 repeated int32 shard_serialize_formats = 6;
11
12 // Below fields only used for protocol [Semi2k]
13 repeated TripleConfigProposal triple_configs = 50;
14}
SSProtocolProposal 中的 supported_protocols 字段的定义如下:
1enum ProtocolKind {
2 PROTOCOL_KIND_UNSPECIFIED = 0;
3 PROTOCOL_KIND_SEMI2K = 1;
4 PROTOCOL_KIND_ABY3 = 2;
5}
SSProtocolProposal 中的 field_types 字段的定义如下:
1enum FieldType {
2 FIELD_TYPE_UNSPECIFIED = 0;
3 FIELD_TYPE_32 = 1; // Ring 2^32
4 FIELD_TYPE_64 = 2; // Ring 2^64
5 FIELD_TYPE_128 = 3; // Ring 2^128
6}
SSProtocolProposal 中的 trunc_modes 字段的定义如下:
1message TruncationModeProposal {
2 repeated int32 supported_versions = 1;
3
4 int32 method = 2 ; // enum TruncMode
5 repeated int32 compatible_protocols = 3; // protocols that support this method. 如果留空,表示所有 protocol 都支持
6
7 // Below fields only used for trunc method "TRUNC_PRECISE"
8 // ...
9}
TruncationModeProposal 中的 method 字段的定义如下:
1enum TruncMode {
2 TRUNC_MODE_UNSPECIFIED = 0;
3 TRUNC_MODE_PROBABILISTIC = 1;
4 TRUNC_MODE_PRECISE = 2;
5}
SSProtocolProposal 中的 prg_configs 字段的定义如下:
1// Pseudorandom number generator configuration.
2message PrgConfigProposal {
3 repeated int32 supported_versions = 1;
4
5 // enum CryptoType
6 int32 crypto_type = 2;
7}
PrgConfigProposal 中的 crypto_type 字段的定义如下:
1enum CryptoType {
2 CRYPTO_TYPE_UNSPECIFIED = 0;
3 CRYPTO_TYPE_AES128_CTR = 1;
4 CRYPTO_TYPE_SM4_CTR = 2;
5}
SSProtocolProposal 中的 shard_serialize_formats 字段的定义如下:
1// 秘密分享分片的序列化格式
2enum ShardSerializeFormat {
3 SHARED_SERIALIZE_FORMAT_UNSPECIFIED = 0;
4 SHARED_SERIALIZE_FORMAT_RAW = 1;
5}
SSProtocolProposal 中的 triple_configs 字段的定义如下:
1// TrustedThirdParty configs.
2message TripleConfigProposal {
3 repeated int32 supported_versions = 1;
4
5 // TTP 服务的版本号,与 TTP 服务建立会话时需要该字段
6 int32 sever_version = 2;
7}
如果算法是 SS-LR,则 HandshakeRequest 中的 io_param 字段格式如下:
1message LrDataIoProposal {
2 repeated int32 supported_versions = 1;
3
4 // 样本数量
5 int64 sample_size = 2;
6
7 // 特征数量
8 int32 feature_num = 3;
9
10 // 是否有标签(Y)
11 bool has_label = 4;
12}
握手请求的结果 HandshakeResponse 定义如下:
1message HandshakeResponse {
2 // response header
3 ResponseHeader header = 1;
4
5 //** AI/BI 算法层 **//
6
7 // algos = enum AlgoType
8 int32 algo = 2;
9
10 // 算法详细握手参数
11 // SS-LR:learning_rate,optimizer,normalize
12 // ECDH-PSI:Nothing,skip
13 google.protobuf.Any algo_param = 3;
14
15 //** 安全算子层 **//
16
17 // AI/BI 算法所需的 op 列到此处
18 // op = enum OpType
19 // ECDH-PSI:Nothing,skip
20 repeated int32 ops = 4;
21 repeated google.protobuf.Any op_params = 5;
22
23 //** 密码协议层 **//
24
25 // protocol_family = enum ProtocolFamily
26 // SS: Protocol: [Semi2K, ABY3], FieldType, BeaverConfig, SerializeFormat
27 // ECC: Hash2Curve, EcGroup, SerializeFormat
28 // PHE: Protocol: [Paillier, EcElgamal], SerializeFormat
29 repeated int32 protocol_families = 6;
30 repeated google.protobuf.Any protocol_family_params = 7;
31
32 //** 数据 IO **//
33
34 // 定义 AI/BI 算法的输入和结果输出格式,不包括中间交互数据的格式
35 // PSI: item_count、result_to_rank
36 // SS-LR: sample_size、feature_num、has_label, etc.
37 google.protobuf.Any io_param = 8;
38}
其中 ResponseHeader 定义如下:
1syntax = "proto3";
2
3package org.interconnection;
4
5// 31100xxx is the white box interconnection code segment
6// 31100xxx 为引擎白盒互联互通号段
7enum ErrorCode {
8 OK = 0;
9
10 GENERIC_ERROR = 31100000;
11 UNEXPECTED_ERROR = 31100001;
12 NETWORK_ERROR = 31100002;
13
14 INVALID_REQUEST = 31100100;
15 INVALID_RESOURCE = 31100101;
16
17 HANDSHAKE_REFUSED = 31100200;
18 UNSUPPORTED_VERSION = 31100201;
19 UNSUPPORTED_ALGO = 31100202;
20 UNSUPPORTED_PARAMS = 31100203;
21}
22
23message ResponseHeader {
24 int32 error_code = 1;
25 string error_msg = 2;
26}
如果算法是 SS-LR,则 HandshakeResponse 中的 algo_param 字段格式如下:
1message LrHyperparamsResult {
2 // 版本号
3 int32 version = 1;
4
5 // 选中的优化器
6 // Ref: enum Optimizer
7 int32 optimizer_name = 2;
8
9 // 优化器参数
10 // 参考 optimizer.proto
11 google.protobuf.Any optimizer_param = 3;
12
13 // mini-batch 梯度下降的 epoch 参数
14 int64 num_epoch = 4;
15
16 // mini-batch 梯度下降的 bach_size 参数
17 int64 batch_size = 5;
18
19 // ref enum LastBatchPolicy
20 int32 last_batch_policy = 6;
21
22 // L0 正则项
23 double l0_norm = 7;
24
25 // L1 正则项
26 double l1_norm = 8;
27
28 // L2 正则项
29 double l2_norm = 9;
30}
如果 LR 优化器类型是 SGD,则 HandshakeResponse 中的 optimizer_param 字段格式如下:
1// mini-batch (stochastic) gradient descent
2message SgdOptimizer {
3 double learning_rate = 1;
4}
如果安全算子类型是 Sigmoid,则 HandshakeResponse 中的 op_params 字段格式如下:
1message SigmoidParamsResult {
2 int32 version = 1;
3
4 int32 sigmoid_mode = 2;
5}
如果协议族是 SS,则 HandshakeResponse 中的 protocol_family_params 字段格式如下:
1message SSProtocolResult {
2 int32 version = 1;
3 int32 protocol = 2; // enum ProtocolKind
4
5 int32 field_type = 3;
6 TruncationModeResult trunc_mode = 4;
7 PrgConfigResult prg_config = 5;
8
9 // Number of fraction bits of fixed-point number.
10 int32 fxp_fraction_bits = 6;
11
12 // 秘密分享分片的序列化格式, enum ShardSerializeFormat
13 int32 shard_serialize_format = 7;
14
15 // Below fields only used for protocol [Semi2k]
16 TripleConfigResult triple_config = 50;
17}
SSProtocolResult 中的 trunc_mode 字段的定义如下:
1message TruncationModeResult {
2 int32 version = 1;
3
4 int32 method = 2; // enum TruncMode
5}
SSProtocolResult 中的 prg_config 字段的定义如下:
1// Pseudorandom number generator configuration.
2message PrgConfigResult {
3 int32 version = 1;
4
5 // // enum CryptoType
6 int32 crypto_type = 2;
7}
SSProtocolResult 中的 triple_config 字段的定义如下:
1// TrustedThirdParty configs.
2message TripleConfigResult {
3 int32 version = 1;
4
5 // TrustedThirdParty beaver server's remote ip:port or load balancing uri.
6 string server_host = 2;
7
8 // TTP 服务的版本号,与 TTP 服务建立会话时需要该字段
9 int32 sever_version = 3;
10
11 // 与 TTP 服务的会话ID
12 string session_id = 4;
13
14 // 哪一方调用 TTP 服务的 Adjust 接口,与 TTP 服务建立会话时需要该字段
15 int32 adjust_rank = 5;
16}
如果算法是 SS-LR,则 HandshakeResponse 中的 io_param 字段格式如下:
1message LrHyperparamsResult {
2 // 版本号
3 int32 version = 1;
4
5 // 选中的优化器
6 // Ref: enum Optimizer
7 int32 optimizer_name = 2;
8
9 // 优化器参数
10 // 参考 optimizer.proto
11 google.protobuf.Any optimizer_param = 3;
12
13 // mini-batch 梯度下降的 epoch 参数
14 int64 num_epoch = 4;
15
16 // mini-batch 梯度下降的 bach_size 参数
17 int64 batch_size = 5;
18
19 // ref enum LastBatchPolicy
20 int32 last_batch_policy = 6;
21
22 // L0 正则项
23 double l0_norm = 7;
24
25 // L1 正则项
26 double l1_norm = 8;
27
28 // L2 正则项
29 double l2_norm = 9;
30}
Protobuf 传输方式#
Protobuf 传输使用《传输层白盒互联互通协议》中的 P2P 传输协议进行传输。其中传输的 key 按照《传输层白盒互联互通协议》中定义的方法生成, value 即为 protobuf 序列化之后的二进制字符串。
算法主体#
在协议主体运行阶段,SS-LR 基于 mini-batch 梯度下降训练方法,对于每一个 batch,协议的执行过程中,底层都是用 SPDZ Semi2k 秘密分享协议, 以确保计算过程中每一个变量都处在 Arithmetic Sharing 状态,每一方仅能看到本地分片值,看不到明文值,保证了算法执行过程中没有泄露原始信息。
LR 算法训练过程#
LR 算法公式为:
其中 \(x\) 表示特征项,\(w\) 是 LR 模型的权重,\(intercept\) 是截距项, \(w\) 和 \(intercept\) 都是可训练的参数, \(sigmoid\) 是一个 S 型函数,公式如下:
在隐私计算场景下,Sigmoid 函数直接计算有困难,本文件使用近似函数计算的方案,详见 Sigmoid算子
此外,为了统一 \(w\) 和 \(intercept\) 的形式,简化计算流程,我们将 \(intercept\) 也看作是 \(w\) 向量的一个元素, 即假设特征数为 \(k\) 个,则 \(w\) 向量的长度为 \(k+1\),之后在计算时,我们在 \(x\) 的最后拼接一个 \(1\), 即可直接计算向量内积 \(w*x\), 简化计算步骤。
在实际训练时,LR 模型训练采用 mini-batch 梯度下降方法,重复执行如下五个步骤,直到达到目标迭代次数:
第一步:计算预测值 \(pred=sigmoid(batch\_x*w)\)
第二步:计算误差 \(err=pred-y\)
第三步:计算梯度 \(grad=transpose(batch\_x)*err\)
第四步:梯度加正则项 \(grad=grad + w^{'}*l2\_norm\)
第五步:更新模型参数 \(w=w-(grad*learning\_rate/batch\_size)\)
其中:
\(batch\_x\) 是当前 batch 的样本数据集与常数项组成的矩阵,其中常数项为 \(1\),位于 \(batch\_x\) 的最后一列;
\(w\) 是 LR 模型训练的结果,初始值为 \(0\);
\(sigmoid()\) 是常被用作神经网络的激活函数,将变量映射到 \(0\), \(1\) 之间;
\(*\) 是乘法;
\(y\) 是当前 batch 的标签矩阵;
\(transpose()\) 是矩阵转置操作;
\(w^{'}\) 是将 \(w\) 的截距项即最后一个元素置为 \(0\);
\(l2\_norm\) 是 l2 正则项;
\(learning\_rate\) 是学习率参数;
\(batch\_size\) 是每个 batch 的大小。
基于 Semi2K 的纵向 SS-LR 算法#
这里描述基于 Semi2K 协议的两方秘密分享纵向 LR 算法的计算过程。
数据集初始化#
各参与方首先对输入的样本数据 \(batch\_x\) 和标签矩阵 \(y\) 进行编码和秘密分片。
输入数据编码
输入数据集的元素类型为浮点数类型,将其按统一的放大系数转为定点数,然后去掉小数部分转为整数,在整数环上计算。编码方式如下表所示, 整数环可取长度 64、128 等,元素编码后的数据类型分别为 int64_t、int128_t。放大系数和整数环的比特数在握手协议中约定。
实际数据类型 |
整数环的比特数 |
编码数据类型(ISO C99) |
|---|---|---|
浮点数 |
64 |
int64_t |
浮点数 |
128 |
int128_t |
输入数据秘密分享
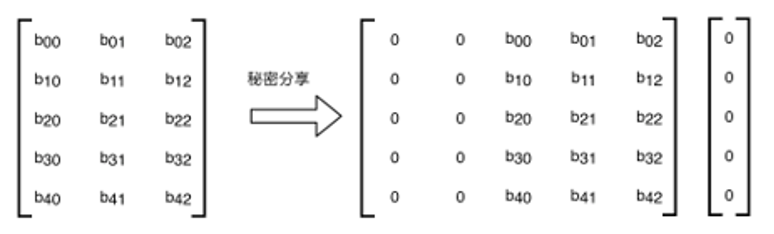
双方根据握手协议确定的样本数量、特征数量和标签信息,以及各自的输入样本数据集,首先通过秘密分享的方式计算出初始密态样本数据集。 对于每个样本元素 \(x\),秘密分享获得两个密态分片 \(x\) 和 \(0\) ( \(x=x+0\) ),将 \(x\) 留在本地,将 \(0\) 发给对方 (由于 \(0\) 不是随机数,所以省略这个发送过程)。
若样本总数量等于5,样本特征数量等于数组 [2, 3],参与方 A(rank=0)拥有2个维度的特征和5个样本的标签,参与方 B(rank=1)拥有3个维度的特征。
双方对样本数据集进行秘密分享。参与方 A 初始化秘密分享的结果如下图:

参与方 B 初始化秘密分享的结果如下图:
交换伪随机数种子
双方各有一个属于自己的伪随机数种子,用于将公共明文转为密文,详见 公共明文转为密文。初始阶段双方向对方发送这个伪随机数种子。
向Beaver服务发送伪随机数种子
除了上一节的伪随机数种子,双方还各自持有另一个伪随机数种子,用于从第三方可信 Beaver 服务获取乘法三元组,详见 Beaver 矩阵乘法三元组。初始阶段双方分别向 Beaver 服务发送自己的这个伪随机数种子。
伪随机数生成方式#
密码学安全的伪随机数生成器应当按照美国 NIST SP800-90A 标准或者中华人民共和国密码行业标准《GM/T 0105-2021软件随机数发生器设计指南》中规定的方式实现。伪随机数的安全强度要达到128比特。
安全算子#
Sigmoid算子
在 Semi2K 协议下无法直接计算 Sigmoid 函数,本文件使用近似计算方案。Sigmoid有多种拟合算法,其中一种较为简单,并且不需要交互的近似计算方法如下:
Minimax逼近方法,其公式为:\(f(X)=0.5+0.125*X\)。
Semi2k算子
公共明文转为密文
将 \(batch\_x\) 常数项 \(1\) 转为密文,将 \(w^{'}\) 的截距项 \(0\) 转为密文,这两处涉及公共明文转为密文。
假设公共明文等于 \(p\),参与方 A 使用自己的伪随机数种子生成随机数 \(r_0\),B 使用自己的伪随机数种子生成随机数 \(r_1\), 生成方式参照 伪随机数生成方式。由于双方都知道对方的伪随机数种子,且双方维护的计数器始终保持一致,所以可以计算出对方生成的伪随机数。 最终,A 的密态分片等于 \(p+r_0-r_1\),B 的密态分片等于 \(r_1-r_0\)。
明文常量 × 密文向量
Sigmoid 的 Minimax 逼近公式和梯度加正则项公式中涉及明文常量与密文向量相乘,即 \(0.125*X\),\(w^{'}*l2\_norm\)。 此算子不涉及参与方之间的通信,双方各自在本地将明文常量与密文分片直接相乘即可。
明文常量 + 密文向量
Sigmoid 的 Minimax 逼近公式中涉及明文常量与密文向量相加,即 \(0.5+0.125*X\)。
对于两个参与方(参与方 A 为 rank 0,参与方 B 为 rank 1)的情况,将明文常量直接加在 A 方的密文分片上,B 方的密文分片不变。
密文向量 + 密文向量
梯度更新公式 \(grad=grad+w^{'}*l2\_norm\) 涉及密文向量与密文向量相加。
此算子不涉及参与方之间的通信,双方在本地将两个密文的分片直接相加即可。
密文向量 - 密文向量
误差计算公式 \(err=pred-y\) 涉及密文向量与密文向量相减。此算子不涉及参与方之间的通信,双方在本地将两个密文的分片直接相减即可。
密文矩阵 * 密文矩阵
公式 \(batch\_x*w\) 和公式 \(grad=transpose(batch\_x)*err\) 涉及密文矩阵与密文矩阵相乘。算子的实现定义如下:
\(X_i\)、\(Y_i\) (\(i=0\) 或 \(1\)) 分别是 \(X\)、\(Y\) 的密文分片,以下步骤是计算 \(Z_i=[X*Y]_i\) 的实现。
可信第三方生成 Beaver 矩阵乘法三元组(\(A_i\),\(B_i\),\(C_i\)),生成方式参见 Beaver 矩阵乘法三元组。
双方同时解密得到 \(X-A\) 和 \(Y-B\):
双方分别本地计算 \(X_i-A_i\) 和 \(Y_i-B_i\) ,然后调用传输层协议接口先后获得对方的分片 \(X_{1-i}-A_{1-i}\) 和 \(Y_{1-i}-B_{1-i}\)。双方分别在本地执行加法后得到 \(X-A\) 和 \(Y-B\)。
各方分别在本地执行以下计算:
\(Z_i=C_i+(X-A)*B_i+A_i*(Y-B)+(1-i)×(X-A)*(Y-B)\)
对 \(Z_i\) 进行截断,截断的实现方式参照 密文截断
密文截断
乘法计算后要对结果进行截断(Truncation)。有多种对秘密分享分片截断的方案,其中一种不需要交互但有一定出错概率的截断算法方案如下:
一方直接对其分片向右移动指定截断位数,另一方用 \(2^n\) 减分片,将减法结果向右移动指定截断位数,再用 \(2^n\) 减右移后的分片。
此处的移动指逻辑右移,即对于 int64/int128 变量,如果数值为自然数,右移时高位补 \(0\),如果数值为负数,右移时高位补 \(1\)。
Beaver 矩阵乘法三元组#
在矩阵乘法计算过程中,参与方 A 和 B 获得矩阵乘法三元组分片(\(A_0\),\(B_0\),\(C_0\))和(\(A_1\),\(B_1\),\(C_1\)),满足 \((A_0+A_1)*(B_0+B_1)=(C_0+C_1)\)。三元组分片是各方通过私有的随机数种子生成的,所以对另一方不可见。
Beaver 三元组生成方式#
乘法三元组有多种实现算法方案,包括两方实现的算法方案和第三方辅助的算法方案。以下是一种第三方辅助的算法方案的实现设计。
以可信第三方的 Beaver 服务为例。Beaver 服务器知道参与方 A 和参与方 B 的随机数种子,通过相同的伪随机数生成算法和参数生成与 A 和 B 相同的伪随机数,即三元组分片分片(\(A_0\),\(B_0\),\(C_0\))和(\(A_1\),\(B_1\),\(C_1\))。Beaver服务计算 \(adjust=(A_0+A_1)*(B_0+B_1)-(C_0+C_1)\),得到调整值 \(adjust\)。参与方 A(或参与方 B)从Beaver 服务获取 \(adjust\) 值,并将其加到 \(C_0\) (或 \(C_1\))分片上得到新的 \(C_0\) (或 \(C_1\)),最终得到的就是符合条件的矩阵乘法三元组。